Regional Yield Forecasting Using Planetary Variables
Planetary Variables (PV) offer deep insights into the state of the soil and vegetation. We can use these insights to forecast crop yield. Here we show an example on how to make a crop yield forecast using multiple Planetary Variables. We are going to predict the yield of hay in the US state of North Dakota using three Planetary Variables: Soil Water Content, Land Surface Temperature, and Vegetation Optical Depth. In this notebook, we show how to make a yield forecast for 2024 using a simple Python algorithm.
Hay yield in North Dakota
Agriculture is an important economic sector in the US state of North Dakota, and about 90 percent of its land area is used for farming. From our Planet Satellites, North Dakota can clearly be classified as an agricultural state:
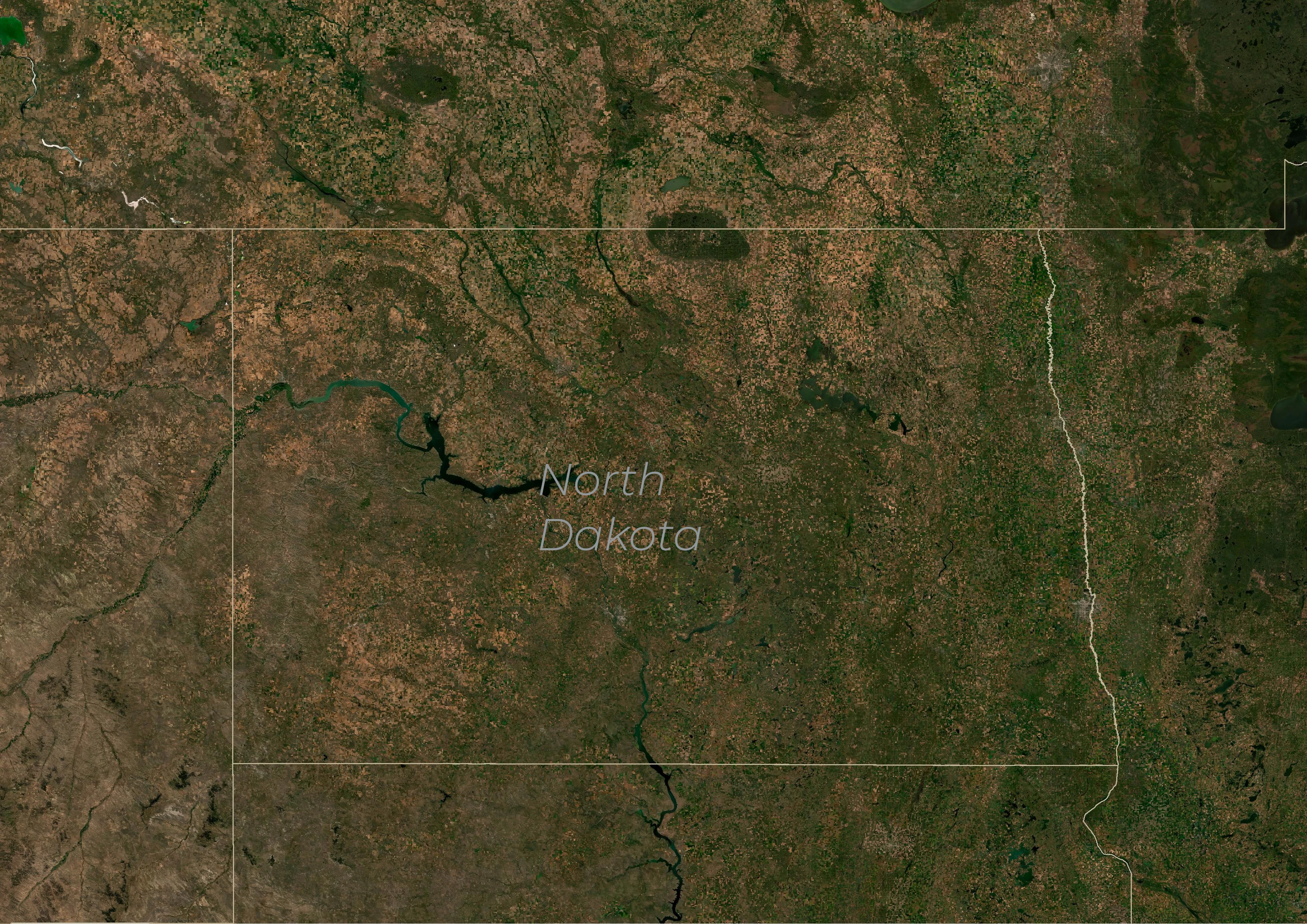
North Dakota (Planet Basemaps July-October 2024)
Most of the state is indeed covered by farm- and grassland, and we only see a few densely-vegetated and urban areas.
Hay, used as forage, is one of the most-produced crops. The US Department of Agriculture (USDA) estimated the value of the produced hay in North Dakota to be over 475 million dollars, which makes it the fifth crop in the state, after soybeans, corn, wheat, and canola. Hay typically grows on non-irrigated fields. Therefore, hay yield is susceptible to droughts and heatwaves. USDA keeps track of the amount of harvested hay. By dividing this amount by the acreage of the hay fields, we get the yield. We have obtained the annual yield data for North Dakota from USDA.
Planetary Variables
Over South Dakota, we have a satellite observation of all three Planetary Variables at least every two days. Here, we use the average value of these PV's over the growing season from May to July.
Soil Water Content
Soil Water Content (SWC) is a measurement of the amount of water in the upper layer of the soil. Crops need water for growth, but a too moist soil causes crop damage as well. Therefore, accurate soil water content measurements give insight into the soil conditions needed for healthy crop growth.
To determine soil water content, we use satellite microwave radiometers. The amount of water affects the amount of microwave radiation emitted by the soil, as well as its polarization. From the polarization and intensity measured by the radiometer, we compute soil water content. Generally, the most reliable and accurate microwave frequency band to determine SWC is the L-band. The radiometer on board NASA's SMAP satellite measures radiation in this band. However, since it has been launched in 2015, we only have a relatively short record available for our analysis. An alternative is to use the higher-frequency C band. While slightly less accurate, especially over densely forested regions, it has been continuously recorded by the AMSR2 instrument since 2012. As you can see in the image above, North Dakota is mostly covered with grassland and crops, and thus C-band observations can be used here as well. SWC is expressed as the volume fraction, and has units .
Land Surface Temperature
Planet's Land Surface Temperature (LST) Planetary Variable measures the skin temperature of the Earth surface. Similar to SWC, microwave radiometers are used to determine LST, but using a different frequency band: the Ka-band. Contrary to the commonly-used thermal infrared sensors, for example, MODIS and Sentinel-3, Planet LST is not impeded by clouds.
LST is expressed in .
Vegetation Optical Depth
For SWC and LST, we measure the microwave radiation from the surface. However, the vegetation on top of the surface absorbs some of this radiation. The algorithm that we use to compute soil water content from this radiation (LPRM) computes this absorption, which we express as Vegetation Optical Depth (VOD). The higher the VOD, the more radiation is absorbed.
A high VOD means two things:
- Dense vegetation
- High vegetation water content, which generally means healthier vegetation.
VOD is therefore an indicator of the amount and health of the vegetation. As such, it might be useful for our yield predictor as well.
Showing the Data
First, we import some Python packages for our analysis and then we read the downloaded CSV file and plot a time series of annual yield.
import pandas as pd
pd.options.display.float_format = '{:.3f}'.format
import numpy as np
from scipy.stats import spearmanr, pearsonr
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
try:
from planet_style import set_style
set_style()
cmap_RdBu= mpl.colormaps.get_cmap('planet.pv.lst_diverging')
except ImportError as e:
cmap_RdBu= mpl.colormaps.get_cmap('RdBu_r')
cmap_RdBu.set_bad(color='#d2d2d2')
Yield = pd.read_csv(f"csv/Yield_ND.csv",usecols= ['Year','Value'], index_col='Year').sort_index().rename(columns={'Value':"Yield"})
fig, ax = plt.subplots(figsize=(8,4))
ax.set_title("Hay yield in North Dakota")
Yield.plot.bar(ax=ax, rot=45, legend=False, width=0.8)
ax.set_xlabel('Year')
ax.set_ylabel('Yield (tons acre$^{-1}$)')
fig.tight_layout()
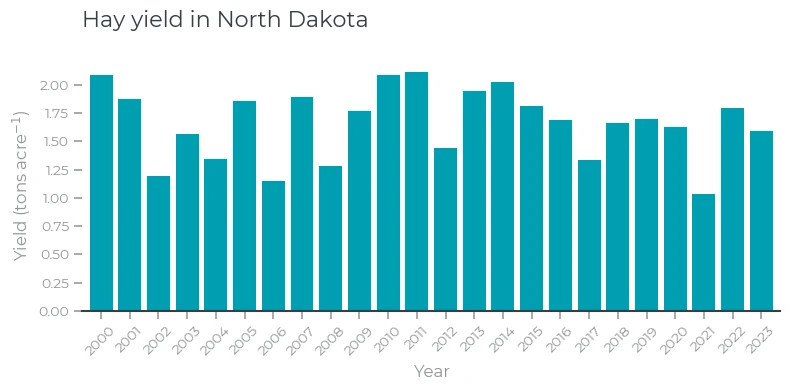
North Dakota (Hay Yield)
The yield of hay in North Dakota varies a lot from year to year. For example, the yields in 2006 and especially in 2021 were only about half the yields in 2000 and 2011. Can we use Planetary Variables to find out whether changes in soil water content or land surface temperature (or both) during the growing season could explain these variations?
Now we have a look into the PV's. We'll start with Soil Water Content:
SWC_daily = pd.read_csv(f"csv/SWC_C_ND.csv",skiprows=6,index_col='date',parse_dates=True).rename(columns={'SM-AMSR2-C1-DESC_V5.0_1000':"SWC"})
SWC_daily = SWC_daily[(SWC_daily.index.month >= 5) & (SWC_daily.index.month < 8) & (SWC_daily.index.year>2012)]
SWC_growing_season = SWC_daily.groupby(SWC_daily.index.year).mean()
Yield_SWC = pd.concat([Yield, SWC_growing_season], axis=1, join="inner")
fig, ax1 = plt.subplots(figsize=(8,4))
ax1.set_title("Yield and Soil Water Content")
Yield_SWC.plot.bar(y='Yield',ax=ax1,width=0.35,rot=45,position=1,legend=False, color='#009db1')
ax1.set_xlabel('Year')
ax1.set_ylabel('Yield (tons acre$^{-1}$)',color='#009db1')
ax1.set_ylim([1.0,2.1])
ax2 = ax1.twinx()
Yield_SWC.plot.bar(y='SWC',ax=ax2,width=0.35,rot=45,position=0,color='#363f43',legend=False)
ax2.set_ylabel('SWC (m$^{3}$ m$^{-3}$)',color='#363f43')
ax2.set_xlim(np.where(Yield_SWC.index == 2013)[0] - 0.5, np.where(Yield_SWC.index == 2023)[0] + 0.5)
ax2.set_ylim([0.19,0.27])
fig.legend(loc="lower center",ncols=2)
fig.subplots_adjust(left=0.05, bottom=0.28, right=0.95, top=0.95, wspace=0.4, hspace=0.2)
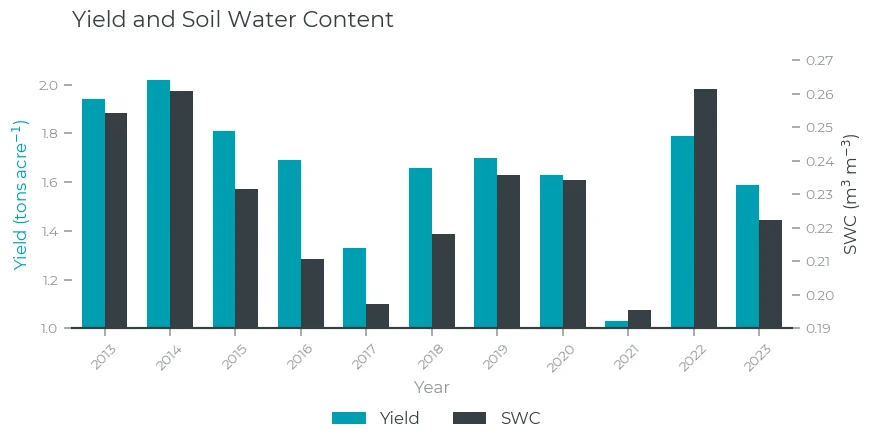
Yield and SWC
At a first glance, SWC and yield show a lot of similarities! Higher soil water content clearly coincides with high yield. During 2017 and 2021, when the yield was the lowest during the 2013-2023 period, the soil was also very dry. However, SWC alone does not explain all the variations: for example, SWC in 2017 and 2021 show similarly low values, but the yield in 2021 was much lower than 2017. Let's see whether we can use LST to explain this. Because we expect that higher temperatures lead to lower yields, we have inverted the LST axis, and the higher the bar, the lower the LST.
LST_daily = pd.read_csv(f"csv/LST_ND.csv",skiprows=6,index_col='date',parse_dates=True).rename(columns={'LST-AMSR2-DESC_V1.0_1000':"LST"})
LST_daily = LST_daily[(LST_daily.index.month >= 5) & (LST_daily.index.month < 8) & (LST_daily.index.year>2012)]
LST_growing_season = LST_daily.groupby(LST_daily.index.year).mean()
LST_gs_negative=-LST_growing_season.rename(columns={'LST':"LST_neg"})+300
Yield_LST = pd.concat([Yield, LST_growing_season, LST_gs_negative], axis=1, join="inner", )
fig, ax1 = plt.subplots(figsize=(8,4))
ax1.set_title("Yield and Land Surface Temperature")
ax1.bar(Yield_LST.index.values-0.175, width=0.35, height=Yield_LST['Yield'].values, color='#009db1', label = 'Yield')
ax1.set_xlabel('Year')
ax1.set_ylabel('Yield (tons acre$^{-1}$)',color='#009db1')
ax1.set_ylim([1.0,2.1])
ax2 = ax1.twinx()
ax2.bar(Yield_LST.index.values+0.175, width=0.35, height = 287, bottom=Yield_LST['LST'].values, color='#363f43', label = 'Land Surface Temperature')
ax2.set_ylim([287, 282.5])
ax2.set_ylabel('LST [K]')
fig.legend(loc="lower center",ncols=2)
fig.subplots_adjust(left=0.05, bottom=0.28, right=0.95, top=0.95, wspace=0.4, hspace=0.2)
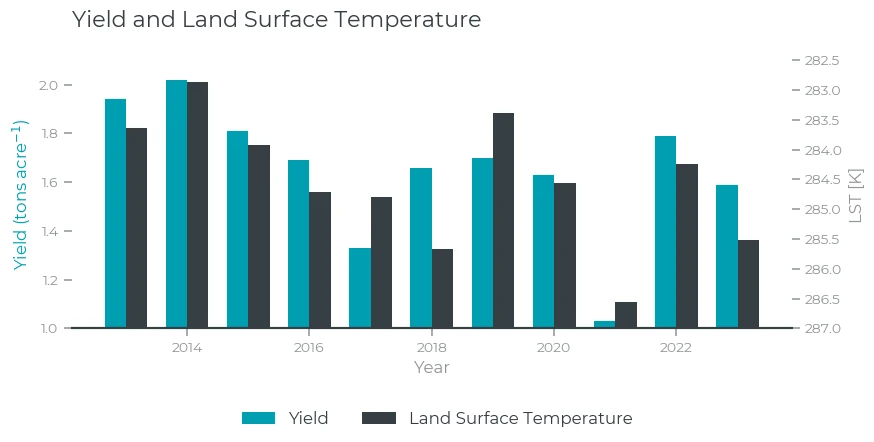
Yield and LST
Here, we indeed find a clear connection: lower LST during the growing season results in higher yield. While SWC showed similar low values for 2017 and 2021, LST shows a lower value for 2021 than for 2017. This suggests that the heat, and not just the drought in 2021 might explain the difference between the yield for both years.
Finally, we have a look into VOD:
VOD_daily = pd.read_csv(f"csv/VOD_C_ND.csv",skiprows=6,index_col='date',parse_dates=True).rename(columns={'VOD-AMSR2-C1-DESC_V5.0_1000':"VOD"})
VOD_daily = VOD_daily[(VOD_daily.index.month >= 5) & (VOD_daily.index.month < 8) & (VOD_daily.index.year>2012)]
VOD_growing_season = VOD_daily.groupby(VOD_daily.index.year).mean()
Yield_VOD = pd.concat([Yield, VOD_growing_season], axis=1, join="inner", )
fig, ax1 = plt.subplots(figsize=(8,4))
ax1.set_title("Yield and Vegetation Optical Depth")
Yield_VOD.plot.bar(y='Yield',ax=ax1,width=0.35,rot=45,position=1,legend=False, color='#009db1')
ax1.set_xlabel('Year')
ax1.set_ylabel('Yield (tons acre$^{-1}$)',color='#009db1')
ax1.set_ylim([1.0,2.1])
ax2 = ax1.twinx()
Yield_VOD.plot.bar(y='VOD',ax=ax2,width=0.35,rot=45,position=0,color='#363f43',legend=False)
ax2.set_ylabel('VOD (m)',color='#363f43')
ax2.set_xlim(np.where(Yield_SWC.index == 2013)[0] - 0.5, np.where(Yield_SWC.index == 2023)[0] + 0.5)
ax2.set_ylim([0.17,0.24])
fig.legend(loc="lower center",ncols=2)
fig.subplots_adjust(left=0.05, bottom=0.28, right=0.95, top=0.95, wspace=0.4, hspace=0.2)
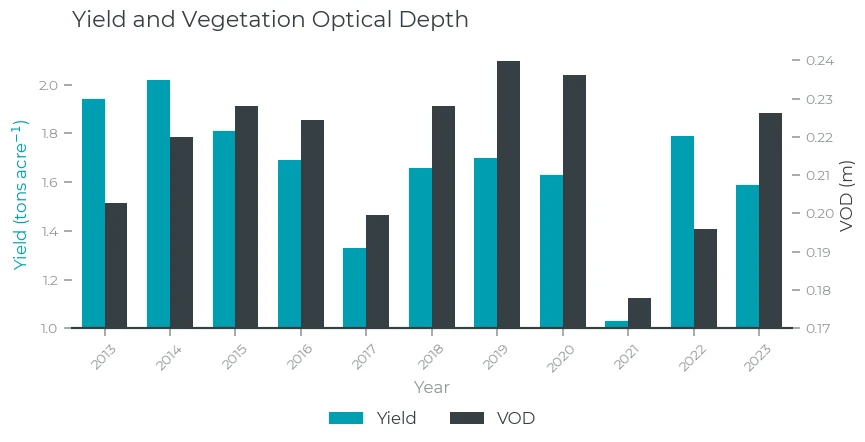
Yield and VOD
Statistics
We now have three variables that show a very similar pattern as the yield: SWC, LST and VOD. Can we say something about which indicator is the best predictor of yield? We can quantify the performance of each predictor by computing correlation coefficients: the higher the correlation between two time series, the higher the similarity between both. Two widely-used correlation coefficients are Spearman and Pearson .
Pearson measures the extent of which deviations from the mean in one time series match with deviations from the mean from the other. Spearman measures the extent of which the rank of the values (from low to high) matches between both.
Both coefficients have a value between -1 and 1. A value of 1 means perfect correlation, and -1 perfect anticorrelation. A value of zero means no correlation (the values are unrelated).
merged_table = pd.concat([Yield, SWC_growing_season, LST_growing_season, VOD_growing_season], axis=1, join="inner")
corr_d = {'Pearson R': [pearsonr(merged_table["Yield"],merged_table['SWC']).statistic,
pearsonr(merged_table["Yield"],merged_table['LST']).statistic,
pearsonr(merged_table["Yield"],merged_table['VOD']).statistic],
'Spearman R': [spearmanr(merged_table["Yield"],merged_table['SWC']).statistic,
spearmanr(merged_table["Yield"],merged_table['LST']).statistic,
spearmanr(merged_table["Yield"],merged_table['VOD']).statistic]}
corr_table = pd.DataFrame(data = corr_d, index = ['SWC', 'LST', 'VOD'])
corr_table
| Pearson R | Spearman R | |
|---|---|---|
| SWC | 0.853 | 0.800 |
| LST | -0.819 | -0.864 |
| VOD | 0.490 | 0.155 |
As expected from the plots, the correlation coefficients are high, especially for LST and SWC. Note the minus sign for LST, which indicates the anti-correlation: low LST values correspond to high yields. VOD has a lower correlation, especially when looking at Spearman , although still positive.
An important question we also need to answer is the correlation between the predictors themselves: are, for example, LST and SWC independent of each other, or are they closely tied? We can compute the correlation coefficients between VOD, LST, and SWC to answer this. Below we compute the correlation coefficients and make a plot.
spearman_r_array = spearmanr(merged_table).statistic[1:,1:]
pearson_r_array = np.corrcoef(merged_table.T)[1:,1:]
fig, axs = plt.subplots(1,2,figsize=(6,3.5))
fig.suptitle("Correlation between LST, SWC, and VOD", fontsize=16)
pcm = axs[0].pcolormesh(np.ma.masked_array(pearson_r_array, np.abs(pearson_r_array) > .9), cmap=cmap_RdBu,vmin=-0.9, vmax=0.9)
axs[1].pcolormesh(np.ma.masked_array(spearman_r_array, np.abs(spearman_r_array) > .9),cmap=cmap_RdBu,vmin=-0.9, vmax=0.9)
axs[0].set_title('Pearson R',fontsize=12, loc='center', pad=6)
axs[1].set_title('Spearman R',fontsize=12, loc='center', pad=6)
for ax in axs:
ax.set_xticks((0.5,1.5,2.5))
ax.set_yticks((0.5,1.5,2.5))
ax.set_xticklabels(['SWC','LST','VOD'])
ax.set_yticklabels(['SWC','LST','VOD'])
ax.spines["top"].set_visible(True)
ax.spines["right"].set_visible(True)
ax.spines["left"].set_visible(True)
fig.subplots_adjust(right=0.95, bottom=0.25,left=0.05,top=0.8, wspace=0.3)
cbar_ax = fig.add_axes([0.2, 0.06, 0.6, 0.05])
cbar = fig.colorbar(pcm, cax=cbar_ax,orientation='horizontal',extend='both')
cbar.ax.tick_params(labelsize=10,pad=5)
cbar.set_label(label='Correlation coefficient',size=10)
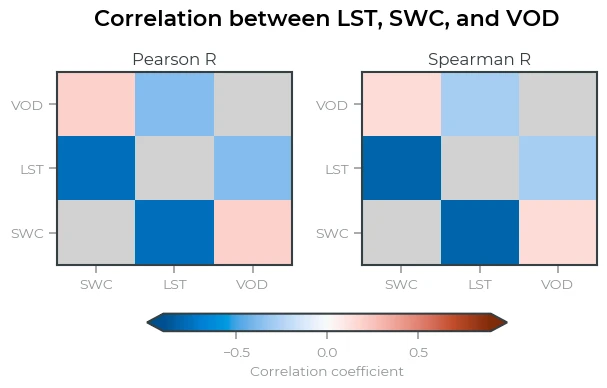
Correlation between LST, SWC, and VOD
Soil Water Content and Land Surface Temperature are highly anti-correlated. From a physical point this makes sense: when the soil is dry, the energy from incoming solar radiation cannot be used to evaporate the water in the soil (for example, latent heat), and thus more energy is used to heat the surface (sensible heat). Conversely, when it is hotter, more water will evaporate and thus the soil becomes drier. The strong anti-correlation implies that there is little additional information in LST observations that is not in the SWC observations. This becomes important when we want to predict yield from a combination of SWC and LST: the added value of two variables over one is probably going to be small.
The correlation between VOD and SWC/LST is much smaller. This means that changes in VOD often differ from changes in LST/SWC and therefore, VOD might add additional predictive information on yield on top of SWC and LST.
Forecasting yield using SWC, LST, and VOD
We have now learned that SWC, LST, and VOD correlate with the yield. Now we want to know whether we can make a more accurate yield prediction using a combination of these three Planetary Variables. Here, we are going to use a simple regression model to find out. We want to solve the following model:
Here is the annual yield in year , and , , and are SWC, LST, and VOD over the growing season in year . A horizontal bar over a variable (for example, ) refers to the climatology: the long-term average value of this quantity, computed over many years. Here, we are interested in the anomalies: the deviation of the yield from its long-term average. We will use the prime () symbol to refer to the anomalies: .
In our regression model, we are going to look for the values of that gives the smallest value of the error squared (). We refer to this solution as the least-squares solution.
In matrix form, we are going to minimize in this equation:
Where we use data from 0 to . There exists a unique solution for this problem. There are a lot of text books on multiple regression, and Wikipedia has a good summary. Here, we use numpy's lscov function to find the solution for us.
Here, we use PV's between 2013 and 2024, while we have yield data until 2023. Therefore, we use the data from 2013-2021 to train the model. Then we predict the yield for 2013-2023. Therefore, the predictions in 2022 and 2023 have not been trained on actual yield.
The first step is finding the climatologies and computing the anomalies.
merged_mean = merged_table[merged_table.index<=2021].mean()
merged_anomalies = merged_table - merged_mean
We have now computed the means:
merged_mean
| Variable | Value |
|---|---|
| Yield | 1.646 |
| SWC | 0.226 |
| LST | 284.455 |
| VOD | 0.217 |
and the anomalies:
merged_anomalies
| Year | Yield | SWC | LST | VOD |
|---|---|---|---|---|
| 2013 | 0.294 | 0.028 | -0.827 | -0.015 |
| 2014 | 0.374 | 0.034 | -1.583 | 0.003 |
| 2015 | 0.164 | 0.005 | -0.538 | 0.011 |
| 2016 | 0.044 | -0.016 | 0.260 | 0.007 |
| 2017 | -0.316 | -0.029 | 0.339 | -0.018 |
| 2018 | 0.014 | -0.008 | 1.206 | 0.011 |
| 2019 | 0.054 | 0.009 | -1.072 | 0.022 |
| 2020 | -0.016 | 0.008 | 0.113 | 0.019 |
| 2021 | -0.616 | -0.031 | 2.100 | -0.040 |
| 2022 | 0.144 | 0.035 | -0.213 | -0.022 |
| 2023 | -0.056 | -0.004 | 1.057 | 0.009 |
Now we can solve the model and show the resulting yield forecast
design_matrix_estimate = np.vstack((np.ones(len(merged_anomalies[merged_anomalies.index<=2021])),merged_anomalies[merged_anomalies.index<=2021]['SWC'], merged_anomalies[merged_anomalies.index<=2021]['LST'],merged_anomalies[merged_anomalies.index<=2021]['VOD'])).T
design_matrix_fcst = np.vstack((np.ones(len(merged_anomalies)),merged_anomalies['SWC'], merged_anomalies['LST'],merged_anomalies['VOD'])).T
solution = np.linalg.lstsq(design_matrix_estimate,merged_anomalies[merged_anomalies.index<=2021]['Yield'])[0]
if "Forecast" not in merged_table:
merged_table.insert(4, "Forecast", merged_mean['Yield']+design_matrix_fcst@solution)
else:
merged_table['Forecast'] = merged_mean['Yield']+design_matrix_fcst@solution
fig, ax = plt.subplots(figsize=(8,4))
ax.set_title("Yield and Forecast")
merged_table.plot.bar(y=['Yield','Forecast'], ax=ax, width=0.8, rot=45, legend=False, color=["#009db1","#363f43"])
ax.set_xlabel('Year')
ax.set_ylabel('Yield (tons acre$^{-1}$)')
ax.set_ylim([1.0,2.1])
fig.legend(loc="lower center",ncols=2)
fig.subplots_adjust(left=0.05, bottom=0.28, right=0.95, top=0.95, wspace=0.4, hspace=0.2)
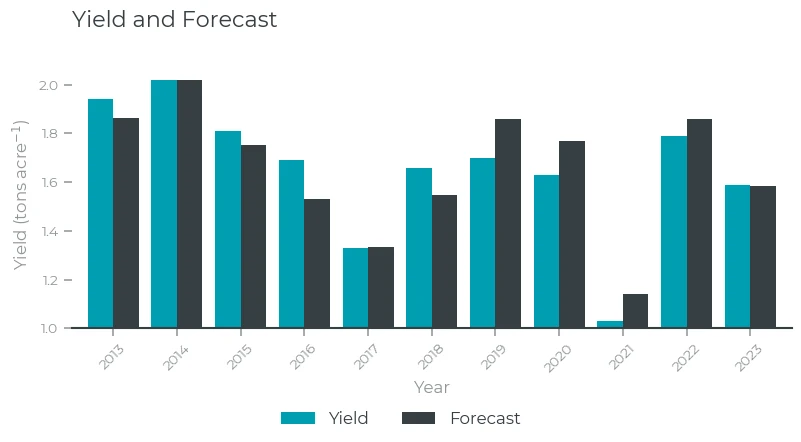
Yield and Forecast
That looks like a good fit! Both for the training period (2013-2021) and for 2022 and 2023.
What are the correlation coeffcients between the forecasted and actual yield?
corr_table = pd.DataFrame(data = {'Correlation coefficient':[pearsonr(merged_anomalies['Yield'], design_matrix_fcst@solution).statistic, spearmanr(merged_anomalies['Yield'], design_matrix_fcst@solution).statistic]}, index = ['Pearson R', 'Spearman R'])
corr_table
| Correlation coefficient | |
|---|---|
| Pearson R | 0.926 |
| Spearman R | 0.845 |
The Pearson correlation coefficient of our model is above the values we got when using a single variable. Spearman R is slightly lower than when only using LST. Keep in mind here that the method that we have chosen (Linear least squares) effectively looks for the solution that provides the highest Pearson correlation coefficient. Other methods, including machine learning techniques, might find a set of coefficients that lead to a higher Spearman R.
But how does our solution look? Let's see:
pd.DataFrame(data = {"value":solution}, index = ['x0','x1','x2','x3'])
| Value | |
|---|---|
| x0 | -0.000 |
| x1 | 7.967 |
| x2 | -0.056 |
| x3 | 3.551 |
What does this mean? The first parameter (), which is the mean value, is essentially zero. That's expected, because we use anomalies throughout, and the mean of the anomalies is zero by definition. The second parameter () sets the yield anomaly due to SWC anomalies. It is positive, which means that a dry soil leads to lower yields. represents the change in yield due to LST changes. Its value is negative: we see lower yields in hotter years. The link with VOD () is again positive. Since VOD is a proxy for the amount of wet vegetation, this is fully expected: when there is more vegetation on the fields, we expect higher yields.
Now we have the values for , we can fill them into our equation, and we have a model to make predictions:
We already have the values of SWC, LST, and VOD for 2024, but the USDA data is not yet available. Let's make an educated guess of the hay yield for 2024 in North Dakota!
First, get the 2024 values for LST, SWC, and VOD, and subtract the climatology:
SWC_anom_2024 = SWC_growing_season.loc[2024]["SWC"] - merged_mean['SWC']
LST_anom_2024 = LST_growing_season.loc[2024]["LST"] - merged_mean['LST']
VOD_anom_2024 = VOD_growing_season.loc[2024]["VOD"] - merged_mean['VOD']
We can fill in these anomalies into the equation above to get our 2024 yield forecast:
Yield_forecast_2024 = (merged_mean['Yield'] + solution[0]
+ solution[1] * SWC_anom_2024
+ solution[2] * LST_anom_2024
+ solution[3] * VOD_anom_2024
)
print("Yield forecast for 2024: %.3f tons acre-1" % Yield_forecast_2024)
Yield forecast for 2024: 1.764 tons acre⁻¹
We have a forecast! Finally, let's plot the time series including the forecast:
fcst = pd.concat((merged_table,pd.DataFrame(index = [2024],data={"Forecast":Yield_forecast_2024})))
fig, ax = plt.subplots(figsize=(8,4))
ax.set_title("Yield and Forecast")
fcst.plot.bar(y=['Yield','Forecast'], ax=ax, width=0.8, rot=45, legend=False, color=["#009db1","#363f43"])
ax.set_xlabel('Year')
ax.set_ylabel('Yield (tons acre$^{-1}$)')
ax.set_ylim([1.0,2.1])
fig.legend(loc="lower center",ncols=2)
fig.subplots_adjust(left=0.05, bottom=0.28, right=0.95, top=0.95, wspace=0.4, hspace=0.2)
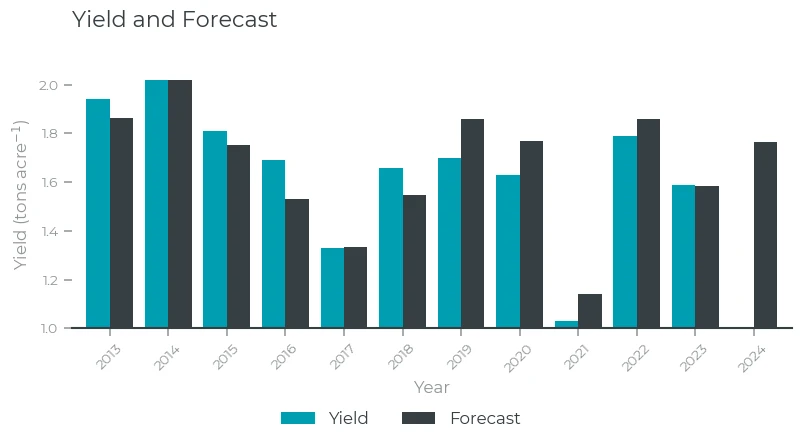
Yield and Forecast (2024)
It looks like 2024 is going to be a good yield year for hay in North Dakota. Now we wait for the USDA numbers for 2024 to see whether we have done a good job. One warning here: this is a pretty simple and not well-validated forecast, so take it with a pinch of salt!
Conclusion
We have made a forecast of the hay yield in North Dakota for the year 2024 using a simple regression with three Planetary Variables (SWC, LST, and VOD). While this analysis is rather simple and lacks the rigorous testing needed to assess the reliability of the regression, it does show that Planetary Variables are a good indicator of crop growth: all three PV's show a clear correlation with the annual yield.
References
Data sources
Planetary Variables
- SWC retrieval algorithm:
- SWC validation:
- LST validation:
- VOD explanation and use cases: